Python爬虫获取物流运输路线
利用Python爬虫批量获取物流(快递EMS)订单列表的运输路线,源码可在Github查看。
Python与爬虫
一直觉得爬虫技术很高大上,然后百度一番发现很多用Python写爬虫,自己以前也没有接触过Python,感觉这是一个学(zhuang)习(bi)的好机会。所以就用如下的测试数据开始了Python的爬虫学习,功能十分简单,代码丑陋:
所谓爬虫,就像利用一只程序员赋予动态思维的“蜘蛛”,首先随机放置于一个网络节点,这只蜘蛛会获取该网络节点中程序认为有用的信息,并将这些有用信息通过相关规则提取出来,形成我们具体想要的数据。一般该网络节点还会有其他网络节点的链接,所以这只“蜘蛛”就会开始新数据找寻之旅,从而获取源源不断的数据。
实现
下面就介绍我们的利用Python爬虫抓取物流(快递)单号的运输路线,首先可用于查询快递运输路线的网站非常多,这里我利用快递100,接下来就是最关键的事情—模拟浏览器环境发送请求,然后获取想要的数据,其中最主要的就是Cookie,我们的请求头设置如下:
header = {
'Accept': '',
'Accept-Encoding': '',
'Accept-Language': '',
'Connection': '',
'Cookie': '',
'User-Agent': ''
}
首先我们需要获取浏览器真实发送请求的各项参数,我们输入正确的订单号(EMS),通过浏览器F12、Network查看本次的请求如下:
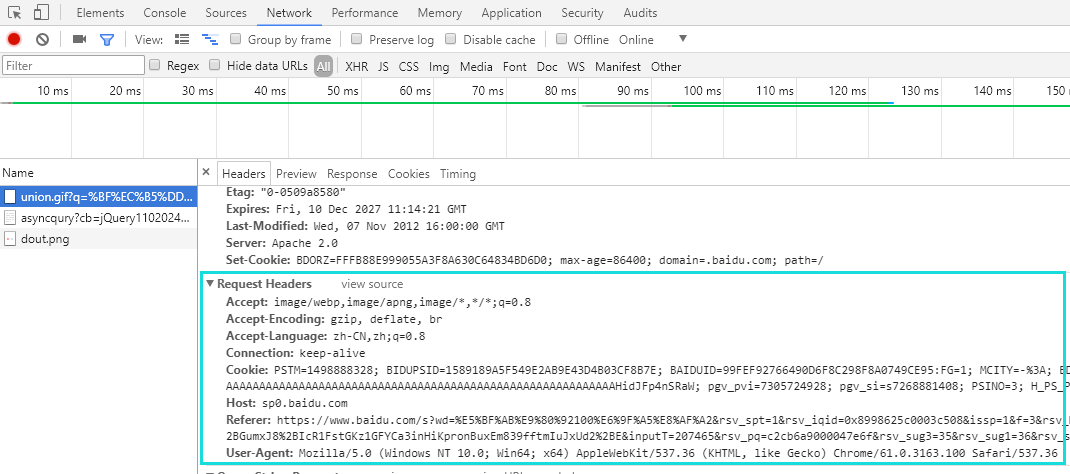
接下来就是将图中与header对应字段属性值填充到我们构造的header中,然后记下本次请求的URL地址,之后我们会动态的变化中间的订单号,从而循环的获取相关物流(快递)单号的信息。其中URL的动态配置与header的其他具体信息请在Github中查看。
获取到相关数据后我们通过一定的数据匹配规则将我们需要的数据提取出来,最终就完成了利用Python爬虫批量获取物流(快递EMS)订单列表的运输路线的功能实现。实现效果如下:
